
I’m a second year undergraduate student from Yuanpei College, Peking University. My research interest includes robotic manipulation, multimodal large models, computer vision, and machine learning.
{kind=link}
Publications
[In Submission] Fast-in-Slow: A Dual-System Foundation Model Unifying Fast Manipulation within Slow Reasoning
Hao Chen, Jiaming Liu, Chenyang Gu, Zhuoyang Liu(equal contribution), Renrui Zhang, Xiaoqi Li, Xiao He, Yandong Guo, Chi-Wing Fu, Shanghang Zhang, Pheng-Ann Heng 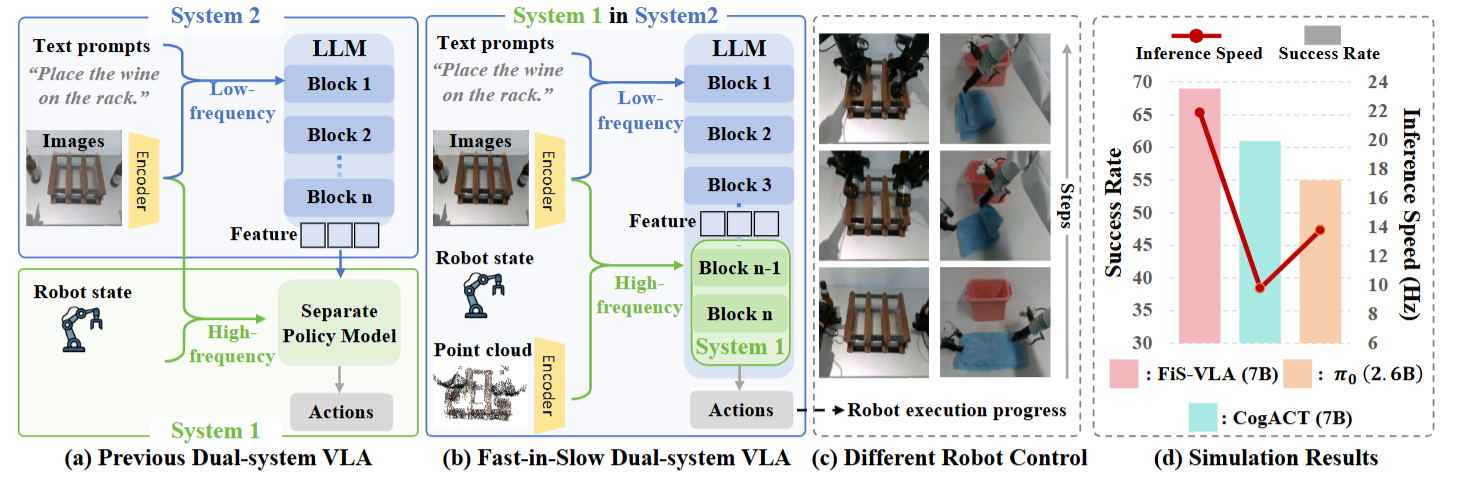 We propose Fast-in-Slow (FiS), a unified dual-system vision-language-action (VLA) model that embeds the System 1 execution module within the VLM-based System 2 by partially sharing parameters. Unlike previous dual-system VLA methods that attach a separate policy head as System 1, FiS-VLA repurposes the final transformer blocks of an intact VLM as System 1, while retaining the full model for System 2 reasoning. [Project Page]/[Paper on Arxiv]/[Github Repo]
We propose Fast-in-Slow (FiS), a unified dual-system vision-language-action (VLA) model that embeds the System 1 execution module within the VLM-based System 2 by partially sharing parameters. Unlike previous dual-system VLA methods that attach a separate policy head as System 1, FiS-VLA repurposes the final transformer blocks of an intact VLM as System 1, while retaining the full model for System 2 reasoning. [Project Page]/[Paper on Arxiv]/[Github Repo]
[In Submission] HybridVLA: Collaborative Autoregression and Diffusion in a Unified Vision-Language-Action Model
Jiaming Liu, Hao Chen, Pengju An, Zhuoyang Liu(equal technical contribution), Renrui Zhang, Chenyang Gu, Xiaoqi Li, Ziyu Guo, Sixiang Chen, Mengzhen Liu, Chengkai Hou, Mengdi Zhao, KC alex Zhou, Pheng-Ann Heng, Shanghang Zhang 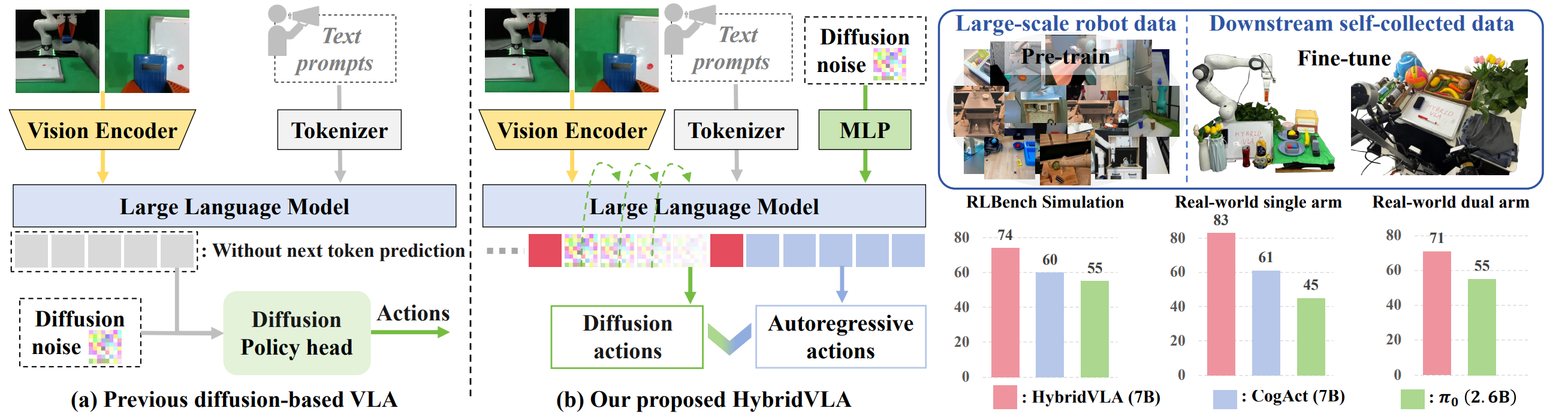 We introduce HybridVLA, a unified framework that absorbs the continuous nature of diffusion-based actions and the contextual reasoning of autoregression within a single large language model. HybridVLA outperforms previous state-of-the-art VLA methods by 14% and 19% in mean success rate on simulation and real-world tasks, respectively, while demonstrating stable manipulation in unseen configurations. [Project Page]/[Paper on Arxiv]/[Github Repo]
We introduce HybridVLA, a unified framework that absorbs the continuous nature of diffusion-based actions and the contextual reasoning of autoregression within a single large language model. HybridVLA outperforms previous state-of-the-art VLA methods by 14% and 19% in mean success rate on simulation and real-world tasks, respectively, while demonstrating stable manipulation in unseen configurations. [Project Page]/[Paper on Arxiv]/[Github Repo]
[In Submission] AC-DiT: Adaptive Coordination Diffusion Transformer for Mobile Manipulation
Sixiang Chen, Jiaming Liu, Siyuan Qian*, Han Jiang, Lily Li, Renrui Zhang, Zhuoyang Liu, Chenyang Gu, Chengkai Hou, Pengwei Wang, Zhongyuan Wang, Shanghang Zhang 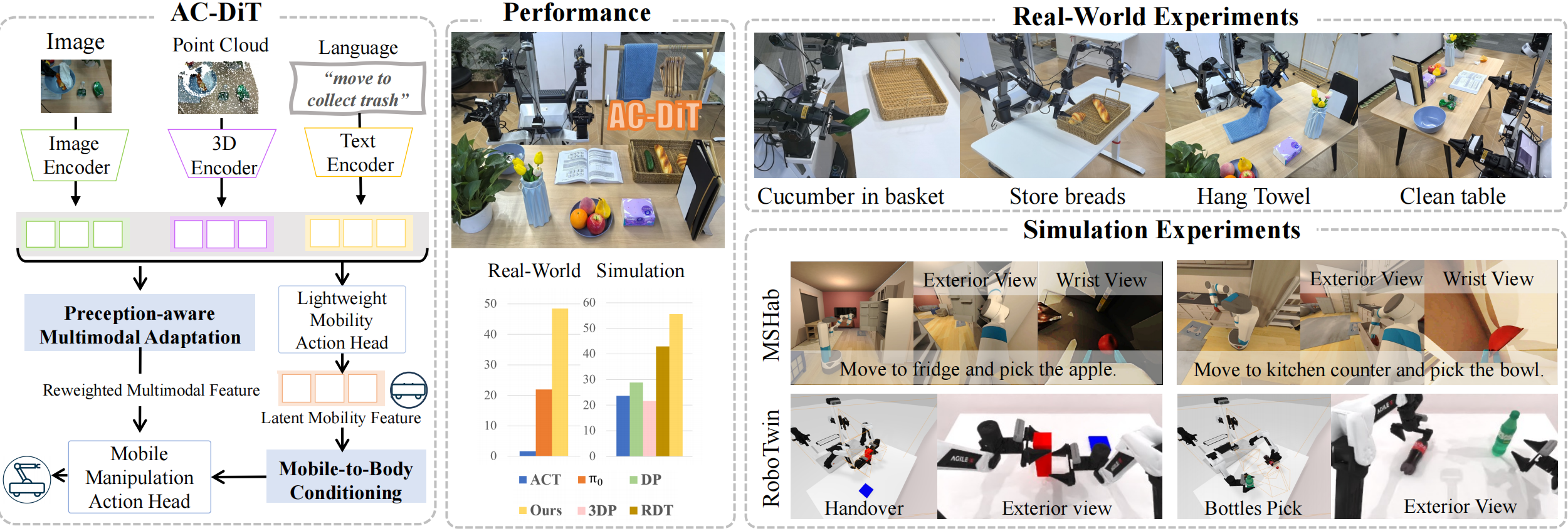 We propose the Adaptive Coordination Diffusion Transformer (AC-DiT), which enhances mobile base and manipulator coordination for end-to-end mobile manipulation. [Project Page]/[Paper on Arxiv]/[Github Repo]
We propose the Adaptive Coordination Diffusion Transformer (AC-DiT), which enhances mobile base and manipulator coordination for end-to-end mobile manipulation. [Project Page]/[Paper on Arxiv]/[Github Repo]
[CVPR 2025 Synthetic Data for Computer Vision Workshop][In Submission] H2R: A Human-to-Robot Data Augmentation for Robot Pre-training from Videos
Guangrun Li, Yaoxu Lyu, Zhuoyang Liu*(equal contribution), Chengkai Hou, Jieyu Zhang, Shanghang Zhang 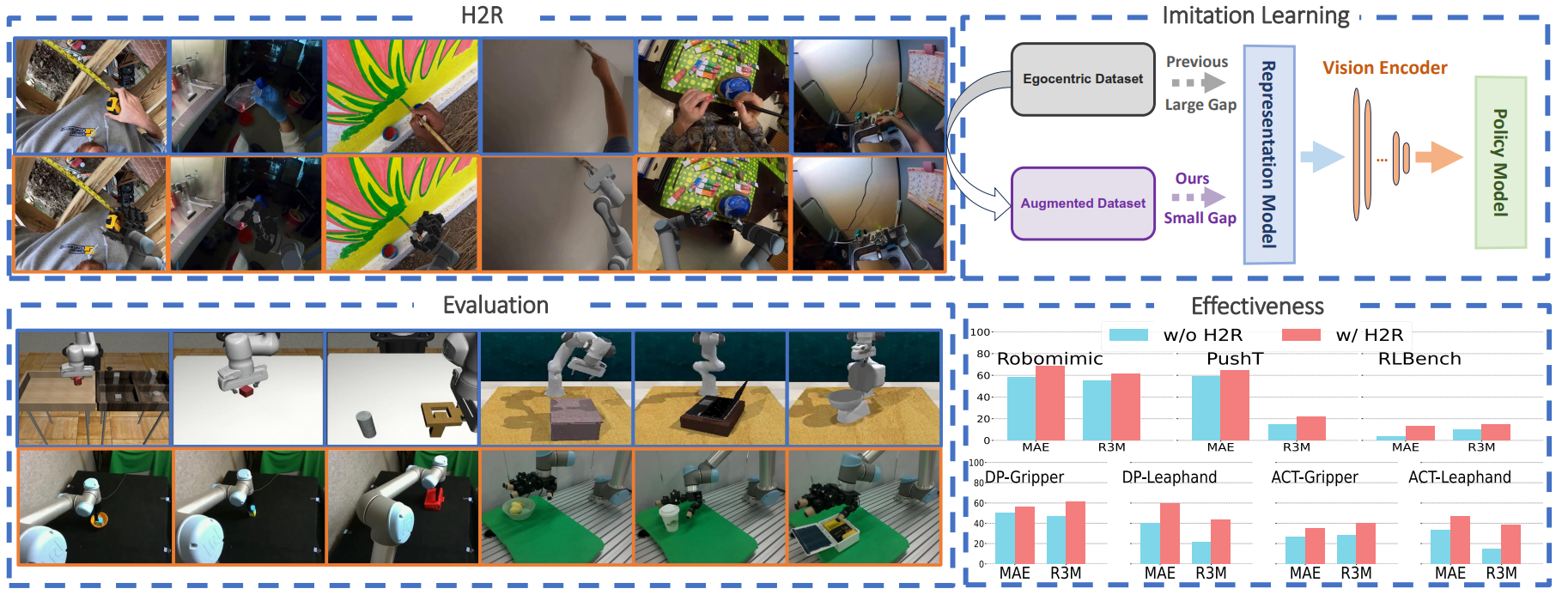 We propose H2R, a simple data augmentation technique that detects human hand keypoints, synthesizes robot motions in simulation, and composites rendered robots into egocentric videos. This process explicitly bridges the visual gap between human and robot embodiments during pre-training. We apply H2R to augment large-scale egocentric human video datasets such as Ego4D and SSv2, replacing human hands with simulated robotic arms to generate robot-centric training data. [Project Page]/[Paper on Arxiv]/[Dataset]
We propose H2R, a simple data augmentation technique that detects human hand keypoints, synthesizes robot motions in simulation, and composites rendered robots into egocentric videos. This process explicitly bridges the visual gap between human and robot embodiments during pre-training. We apply H2R to augment large-scale egocentric human video datasets such as Ego4D and SSv2, replacing human hands with simulated robotic arms to generate robot-centric training data. [Project Page]/[Paper on Arxiv]/[Dataset]